While lawyers and law students do not need an in-depth technical understanding of how generative AI works, a basic grasp will help you understand the technology's strengths and weaknesses for a legal research task.
One easy way to think about any AI system is to think of it in 3 stages or "layers": input, analysis, and output:
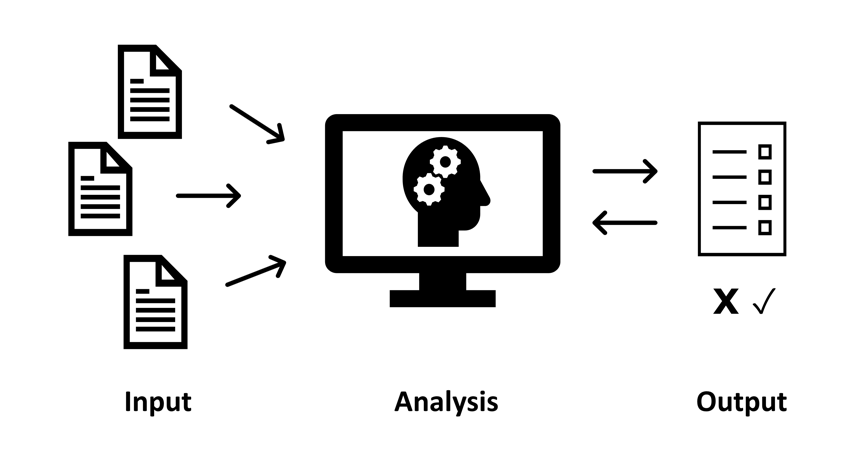
Image credit: Christa Bracci & Erica Friesen, Legal Research Online (eCampus Ontario Open Library, 2024)
These layers feed into each other, which means that the generated text you see as output is highly dependent on the previous two layers.
| Input | Analysis | Output |
|
The dataset (the set of information) that the system runs on. GenAI Examples: input could be one specific case; a whole database of Canadian case law; or a series of databases including case law, legislation, and secondary sources. |
Direct programming + the "black box" (decisions made by the computer for reasons undiscernible to humans). GenAI Examples: a tool might be directly programmed to prioritize more recent cases over older cases, but it may also apply unknown rules to its analysis without explicit training. |
The results generated by the tool in response to a task. GenAI Examples: output could be a generated draft of a research memo, a selection of cases, or a summary of the law based on a question you asked. |
Terminology Note: Input vs User Input (Prompts)
Elsewhere, you may also see the word input used to describe what a user enters into a genAI tool. The model above focuses on elements of the system itself, rather than the way a user interacts with the system.
In this chapter, we refer to user inputs as prompts, since that is the most common type of user input for genAI systems. However, user input can take other forms too, such as feedback to the system (e.g. thumbs up/down to an answer).
GenAI systems in law are usually focused on generating text (versus other types of media) and are built on a type of technology called a Large Language Model.
You can understand what this is by breaking down the phrase:
The most important word here is model. LLMs do not understand the text they are trained on or the text they generate; rather, they use their dataset's underlying patterns to create a complex statistical model that is then used to predict which word or phrase should come next in a sentence.
If we use the 3 layers model, an LLM works by:
Because the output is based on probabilities, this can lead to...
Because it is generated on probabilities, there is always a possibility that the output of an LLM is not factually accurate.
This is how lawyers have been tricked by fake case citations. The model can easily produce something that looks like a real citation, which can be difficult to catch—especially if you are in a rush to complete your research.
These factual inaccuracies are often called hallucinations: false or misleading information fabricated by a genAI system. In legal research, misleading information can appear in multiple different ways. Magesh et al (2024) identified the following three types of hallucinations:
►For more, see Varun Magesh et al, "Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools" (2024) [unpublished, archived at arxiv.org].
Because of the possibility of error, you must take care to integrate genAI into your legal research workflow with some guardrails in place.
Mignanelli (2024) suggests the following workflow for genAI use in legal research:
►See Nicholas Mignanelli, "The Legal Tech Bro Blues: Generative AI, Legal Indeterminacy, and the Future of Legal Research and Writing" (2024) 8:2 Geo L Tech Rev 298.
Even if a genAI tool does not hallucinate in the narrow sense, it may still present incomplete information about the law.
►See Critically Assessing AI-generated Content for more information on mitigating this risk.
These Canadian tools are available either freely online or via the Law Library: